World-Class LLM Engineering Talent
Hire LLM engineers from Bluetris with deep expertise in large language model development, fine-tuning, and optimization. Our engineers have worked on production LLM systems serving millions of users and can help you build powerful AI solutions.
LLM Engineering Services
Comprehensive LLM development from fine-tuning to production deployment
LLM Model Fine-Tuning
Fine-tune GPT, Claude, Llama, and other LLMs on your proprietary data for domain-specific performance and accuracy.
Custom LLM Development
Build custom large language models tailored to your industry, use case, and performance requirements.
Model Optimization
Optimize LLM performance through quantization, pruning, distillation, and efficient inference techniques.
RAG Implementation
Implement Retrieval Augmented Generation systems to enhance LLM responses with your knowledge base.
LLM Integration
Seamlessly integrate LLMs into your applications with robust APIs, streaming, and error handling.
Safety & Alignment
Implement safety measures, content filtering, and alignment techniques for responsible AI deployment.
Performance Monitoring
Set up comprehensive monitoring, logging, and analytics for LLM performance and cost optimization.
Training & Support
Provide team training, documentation, and ongoing support for LLM implementation and maintenance.
Our Engineers' Expertise
OpenAI GPT Models
Expert integration and fine-tuning of GPT-4, GPT-3.5, and OpenAI's latest models for production applications.
Anthropic Claude
Build with Claude's advanced reasoning capabilities, long context windows, and Constitutional AI principles.
Open Source LLMs
Deploy and customize Llama, Mistral, Falcon, and other open-source models for full control and cost efficiency.
Model Fine-Tuning
Expert fine-tuning using LoRA, QLoRA, and full fine-tuning techniques for specialized performance.
Prompt Engineering
Advanced prompt engineering and optimization for maximum model performance and reliability.
Technology Stack
OpenAI API
LangChain
Hugging Face
PyTorch
TensorFlow
Vector Databases
CUDA/GPU
Model Serving
LLM Technology & Architecture
Deep expertise in large language model systems
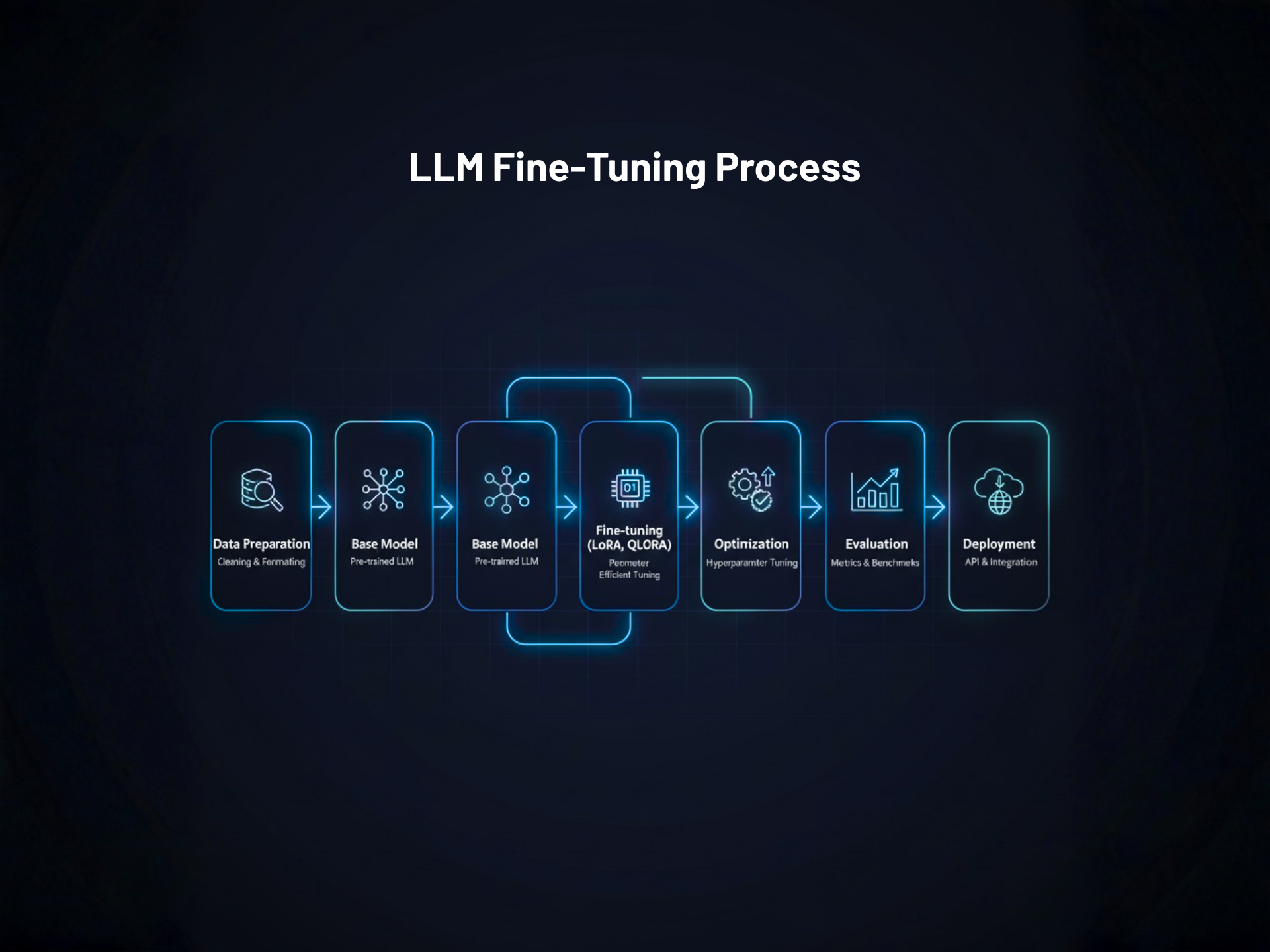
LLM Fine-Tuning Process
LoRA, QLoRA, and model optimization workflows

Transformer Architecture
Multi-head attention and neural networks
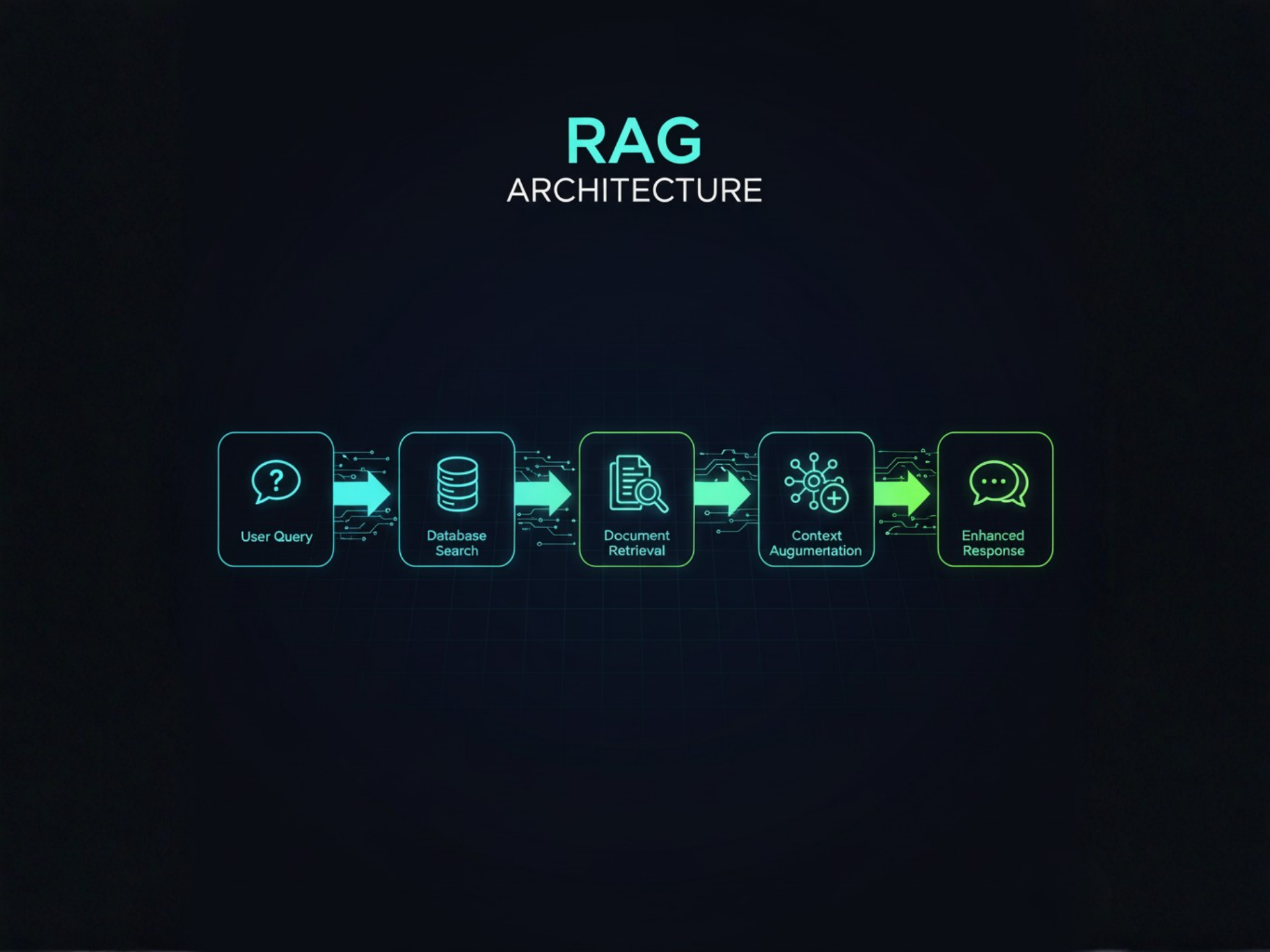
RAG Systems
Retrieval augmented generation architecture
Success Story
See how our experts transformed businesses
Enterprise Knowledge Assistant
Our LLM engineers fine-tuned Llama 2 on company documentation to create an internal knowledge assistant. The system reduced information retrieval time by 80% and improved employee productivity across the organization.
Hire LLM Engineers in 3 Easy Steps
Share Your LLM Requirements
Tell us about your use case, data, and performance goals for custom LLM solutions.
Interview LLM Experts
Review profiles and interview vetted engineers with proven LLM development experience.
Onboard in 24-48 Hours
Start building with your dedicated LLM engineering team immediately.